Enterprise Microservices: What Does It Take?
[Jully 2019]
Adopting a microservices architecture is a significant challenge for any development team. Breaking down a monolithic application into a group of small, decoupled services affects how those services are designed, implemented, tested, and deployed. Particular attention must be paid at the architectural level to identify services, define clear boundaries between them, and ensure that the grouping of all services is well-orchestrated. From the end user's perspective, it should feel as if they are still interacting with a single, unified "monolithic" application.
Here are some areas to consider when adopting a microservices architecture:
The following sample design uses an entry service that reads data (CSV, XML, records, etc.) from external sources (file system, RDBMS, etc.).
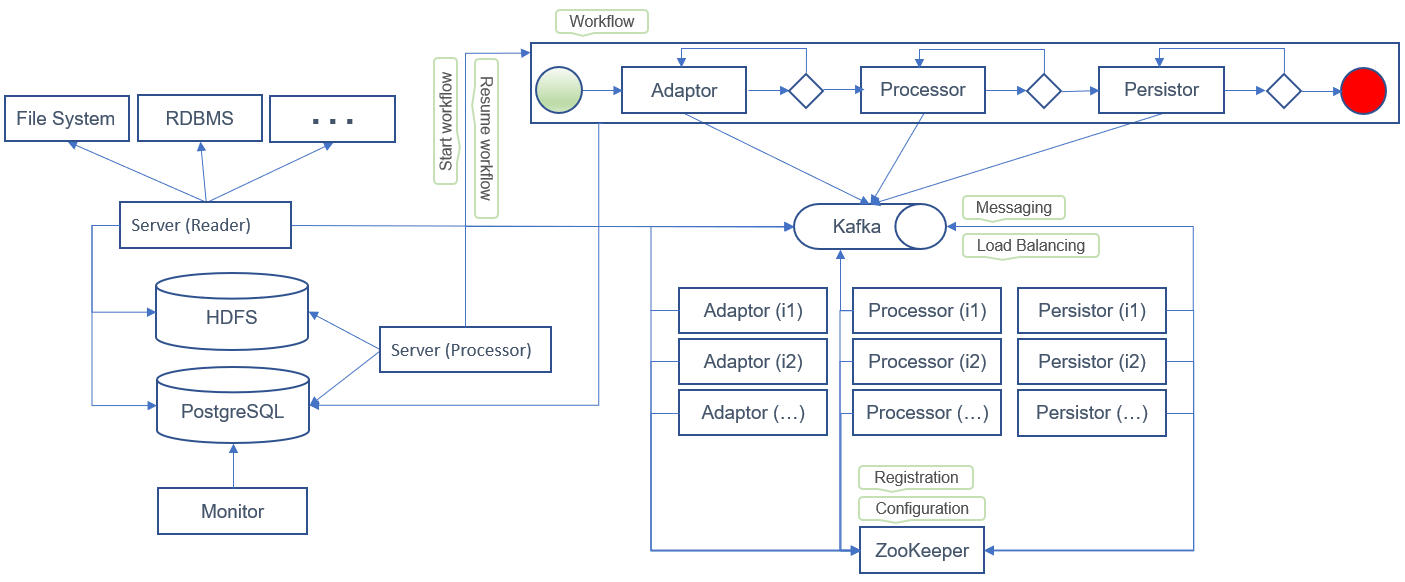
Services subscribe to specific topics and read messages from the messaging system. Each service implements the business logic specific to its task. Upon successful execution, the service adds new parameters to the payload message and submits it to the application’s main topic. The updated message is then read by the entry point, which resumes the workflow for the next task.
If a service fails to execute a task, it should send a new payload message to a retry topic:
Microservices Workflow Automation: jBPM
Using a workflow engine to automate microservices execution simplifies understanding the service flow and helps identify system bottlenecks. It also enables administrators or backend services to resume or cancel processes blocked at specific tasks.
In large enterprise applications, the number of microservices can be extensive. Attempting to design a single process model for all microservices would make the workflow complex and difficult to maintain. Instead, enterprise applications should be structured into multiple business domains. Each domain should have its own workflow and be responsible for orchestrating the services it owns.
It's not always feasible to designate a specific service as the owner or main entry point for all other services. Designing a single workflow to orchestrate all services is often impractical. However, it is possible to define a reasonable number of workflows for major business activities. In some cases, services may need to interact via alternative methods such as REST APIs or messaging systems.
See this page for more information and code samples: Java Business Process Model (jBPM)
Messaging System: Kafka
A messaging system helps decouple communication between workflow tasks and services. It enables easy scaling by allowing new service instances to be created without additional configuration. A service simply subscribes to a topic, reads messages, and executes the relevant task. Load is automatically balanced across instances, with each handling more or fewer tasks depending on the available system resources (CPU, RAM, disk, etc.).
Services must be responsible for notifying task execution failures and implementing retry strategies when needed. Payload messages should include clear metadata so services can interpret the data and make appropriate decisions.
It's possible that a service may consume a message but fail to notify whether the task succeeded or failed. These situations are difficult to manage. A service might complete a task but fail to report it, or fail at both the task and the notification. If a service is frozen or stopped, there's no way to get feedback on the task's status. Workflow engines help track and monitor task execution states and provide mechanisms for resuming or canceling tasks based on triggers like events or timeouts.
Administrators can use dashboards to monitor and manage processes. Additionally, a monitoring service can be implemented to act on tasks using various strategies.
See this page for more information and installation steps: Install and configure Apache Kafka
Securing Service-to-Service Communication: JWT
Two types of service communication are typically considered: external and internal.
External communication involves authentication from an end user or external service. Requests must be authenticated and authorized before any tasks are executed, and sensitive data must be encrypted.
Internal communication occurs between internal services. While authentication may not always be required, services should validate that requests are authorized and originate from legitimate sources. Backend services can use JWT tokens and/or mTLS to enforce secure interactions.
It’s important to classify the type of communication to determine requirements for authentication, authorization, and encryption. JWT (JSON Web Token) provides a secure method to transmit information. A token’s payload contains metadata that identifies the issuer and validates the request (though sensitive data should not be included). Tokens are signed to verify their integrity.
A risk arises if a token is intercepted—it can be reused by unauthorized entities. Payload encryption is possible but requires secure key sharing, which can be challenging in large-scale distributed systems. Tools like ZooKeeper can help by acting as a secure configuration store where services fetch public and private keys.
The payload message should include the JWT token used for request verification.
In scenarios where external users access services via an API gateway, OAuth is essential for authentication and authorization. The API gateway manages the OAuth token and can issue an internal JWT token for communication with internal services. The OAuth token should not contain sensitive data and should reference the authorization server. Internal tokens can contain more data and should be verifiable without contacting the authorization server. Additional fields like issuer identity, service targets, and expiration dates can be added to enforce stricter validation.
Service Configuration: ZooKeeper
Some service configurations are instance-specific and set at startup via environment variables or property files. These typically don't change at runtime; if they do, the service often needs to restart to apply changes.
Other configurations are shared across all instances and require external persistent storage. A common administration service can be initialized first to save default configurations to persistent storage. Once initialized, other service instances can safely start.
Shared configurations should be easy to manage. APIs can be exposed to update settings, and services must be notified when changes occur. ZooKeeper enables distributed services to share and manage configuration data and public keys, ensuring JWT token validation during request handling.
See this page for more information and code samples: Apache ZooKeeper
Logging: Solr
To debug errors, developers often need access to logs from multiple services. This can require logging into multiple hosts, identifying relevant log files, and correlating data across services and instances.
Services should log errors and events in a common schema. Metadata should be divided into two categories:
Indexing logs using Solr provides a centralized, searchable repository. Developers can investigate issues without accessing remote servers directly. Monitoring services can analyze logs to audit services and identify performance issues, bottlenecks, and errors. Solr’s features (faceting, filtering) help narrow searches and generate analytics and reports.
See this page for more information and code samples: Apache Solr
Containerization: Docker
Containerization offers many benefits for microservices development and deployment. It ensures consistent delivery, enables service portability across environments, simplifies installation, and guarantees resource allocation per service. It also facilitates orchestration and makes it easier to scale or deploy new service instances.
See this page for more information and code samples: Docker
Container Orchestration: Kubernetes
Managing large numbers of containers is complex. Container orchestration platforms like Kubernetes address challenges such as deployment, resource management, availability, and scalability.
See this page for more information and code samples: Kubernetes
[Jully 2019]
Adopting a microservices architecture is a significant challenge for any development team. Breaking down a monolithic application into a group of small, decoupled services affects how those services are designed, implemented, tested, and deployed. Particular attention must be paid at the architectural level to identify services, define clear boundaries between them, and ensure that the grouping of all services is well-orchestrated. From the end user's perspective, it should feel as if they are still interacting with a single, unified "monolithic" application.
Here are some areas to consider when adopting a microservices architecture:
-
Performance (Response Time, Throughput, and Scalability)
-
Automation
-
Error Management
-
Reporting
-
Continuous Integration / Continuous Delivery (CI/CD)
-
Provisioning
-
Deployment
-
Configuration Management
-
Containerization
-
Orchestration
The following sample design uses an entry service that reads data (CSV, XML, records, etc.) from external sources (file system, RDBMS, etc.).
-
The entry point of the application generates payload data that is stored in staging storage (e.g., HDFS).
-
It also creates a payload message (including headers, parameters, and variables),
which is used as an entry point to trigger the workflow engine (e.g., jBPM).
-
The payload message also serves as a means of communication between tasks and services in the workflow.
-
Each time a service (processor, task, etc.) acts on the payload data, it produces a new payload message and sends it to a messaging system (e.g., Kafka).
-
The application’s entry point reads the payload message from the messaging system and triggers the workflow engine to resume the service workflow.
Services subscribe to specific topics and read messages from the messaging system. Each service implements the business logic specific to its task. Upon successful execution, the service adds new parameters to the payload message and submits it to the application’s main topic. The updated message is then read by the entry point, which resumes the workflow for the next task.
If a service fails to execute a task, it should send a new payload message to a retry topic:
-
The new payload message should include metadata such as the current retry count.
-
If the retry count reaches the maximum limit,
the message can be redirected to an error topic for later handling by an administrator or backend service.
-
Services must regularly check their retry topics for pending messages.
-
Each service should define a strategy for handling both retry and main topic messages.
-
They should also implement delay strategies that impose a wait time before reading messages from the retry topic.
-
An administrator or backend service should have the ability to resume, retry, or cancel failed tasks.
Microservices Workflow Automation: jBPM
Using a workflow engine to automate microservices execution simplifies understanding the service flow and helps identify system bottlenecks. It also enables administrators or backend services to resume or cancel processes blocked at specific tasks.
In large enterprise applications, the number of microservices can be extensive. Attempting to design a single process model for all microservices would make the workflow complex and difficult to maintain. Instead, enterprise applications should be structured into multiple business domains. Each domain should have its own workflow and be responsible for orchestrating the services it owns.
It's not always feasible to designate a specific service as the owner or main entry point for all other services. Designing a single workflow to orchestrate all services is often impractical. However, it is possible to define a reasonable number of workflows for major business activities. In some cases, services may need to interact via alternative methods such as REST APIs or messaging systems.
See this page for more information and code samples: Java Business Process Model (jBPM)
Messaging System: Kafka
A messaging system helps decouple communication between workflow tasks and services. It enables easy scaling by allowing new service instances to be created without additional configuration. A service simply subscribes to a topic, reads messages, and executes the relevant task. Load is automatically balanced across instances, with each handling more or fewer tasks depending on the available system resources (CPU, RAM, disk, etc.).
Services must be responsible for notifying task execution failures and implementing retry strategies when needed. Payload messages should include clear metadata so services can interpret the data and make appropriate decisions.
It's possible that a service may consume a message but fail to notify whether the task succeeded or failed. These situations are difficult to manage. A service might complete a task but fail to report it, or fail at both the task and the notification. If a service is frozen or stopped, there's no way to get feedback on the task's status. Workflow engines help track and monitor task execution states and provide mechanisms for resuming or canceling tasks based on triggers like events or timeouts.
Administrators can use dashboards to monitor and manage processes. Additionally, a monitoring service can be implemented to act on tasks using various strategies.
See this page for more information and installation steps: Install and configure Apache Kafka
Securing Service-to-Service Communication: JWT
Two types of service communication are typically considered: external and internal.
External communication involves authentication from an end user or external service. Requests must be authenticated and authorized before any tasks are executed, and sensitive data must be encrypted.
Internal communication occurs between internal services. While authentication may not always be required, services should validate that requests are authorized and originate from legitimate sources. Backend services can use JWT tokens and/or mTLS to enforce secure interactions.
It’s important to classify the type of communication to determine requirements for authentication, authorization, and encryption. JWT (JSON Web Token) provides a secure method to transmit information. A token’s payload contains metadata that identifies the issuer and validates the request (though sensitive data should not be included). Tokens are signed to verify their integrity.
A risk arises if a token is intercepted—it can be reused by unauthorized entities. Payload encryption is possible but requires secure key sharing, which can be challenging in large-scale distributed systems. Tools like ZooKeeper can help by acting as a secure configuration store where services fetch public and private keys.
The payload message should include the JWT token used for request verification.
In scenarios where external users access services via an API gateway, OAuth is essential for authentication and authorization. The API gateway manages the OAuth token and can issue an internal JWT token for communication with internal services. The OAuth token should not contain sensitive data and should reference the authorization server. Internal tokens can contain more data and should be verifiable without contacting the authorization server. Additional fields like issuer identity, service targets, and expiration dates can be added to enforce stricter validation.
Service Configuration: ZooKeeper
Some service configurations are instance-specific and set at startup via environment variables or property files. These typically don't change at runtime; if they do, the service often needs to restart to apply changes.
Other configurations are shared across all instances and require external persistent storage. A common administration service can be initialized first to save default configurations to persistent storage. Once initialized, other service instances can safely start.
Shared configurations should be easy to manage. APIs can be exposed to update settings, and services must be notified when changes occur. ZooKeeper enables distributed services to share and manage configuration data and public keys, ensuring JWT token validation during request handling.
See this page for more information and code samples: Apache ZooKeeper
Logging: Solr
To debug errors, developers often need access to logs from multiple services. This can require logging into multiple hosts, identifying relevant log files, and correlating data across services and instances.
Services should log errors and events in a common schema. Metadata should be divided into two categories:
- Main metadata: fields used for search and correlation (e.g., message ID, user ID)
- Extended metadata: detailed fields to help understand the context or cause of the event
Indexing logs using Solr provides a centralized, searchable repository. Developers can investigate issues without accessing remote servers directly. Monitoring services can analyze logs to audit services and identify performance issues, bottlenecks, and errors. Solr’s features (faceting, filtering) help narrow searches and generate analytics and reports.
See this page for more information and code samples: Apache Solr
Containerization: Docker
Containerization offers many benefits for microservices development and deployment. It ensures consistent delivery, enables service portability across environments, simplifies installation, and guarantees resource allocation per service. It also facilitates orchestration and makes it easier to scale or deploy new service instances.
See this page for more information and code samples: Docker
Container Orchestration: Kubernetes
Managing large numbers of containers is complex. Container orchestration platforms like Kubernetes address challenges such as deployment, resource management, availability, and scalability.
See this page for more information and code samples: Kubernetes