LLMs
|
Topic Modeling
- Understanding Topic Modeling
- Implementing Basic Topic Modeling with BERTopic
- Advanced Topic Labeling with Language Models
-
Understanding Topic Modeling
Topic modeling is an unsupervised machine learning technique that automatically discovers abstract topics within a collection of documents. It identifies patterns in word usage and groups documents that share similar themes, providing insights into the underlying structure of large text corpora.
Key Benefits:
- Automatically organize large document collections.
- Discover hidden themes and patterns in text data.
- Reduce dimensionality of text data for more efficient analysis and visualization.
- Enable content recommendation systems and improve search functionality.
- Support exploratory data analysis of textual content across various domains.
Example (to simplify, I used one-word sentences):
Cluster 0: ['cats', 'dogs', 'elephants', 'birds'] ==> topic: animals Cluster 1: ['cars', 'trains', 'planes'] ==> topic: transportation
BERTopic is a modern topic modeling technique that leverages transformer-based embeddings to create more semantically meaningful topics. Unlike classical approaches that rely on bag-of-words representations, BERTopic uses contextual embeddings that capture semantic relationships between words and phrases. In BERTopic, document clusters are formed based on semantic similarity in high-dimensional embedding space and then interpreted as coherent topics.
The topic modeling pipeline in BERTopic follows these sequential steps:
-
Document Embeddings: Convert documents into high-dimensional vector representations using pre-trained transformer models like BERT, RoBERTa, or sentence transformers. These embeddings capture semantic meaning and context.
-
Dimensionality Reduction: Use UMAP (Uniform Manifold Approximation and Projection) to reduce embedding dimensions while preserving local neighborhood structure and global topology of the data.
-
Clustering: Apply HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) to group similar documents into dense clusters, automatically determining the number of topics.
-
Topic Representation: Extract representative keywords for each cluster using TF-IDF weighting or other representation models to create interpretable topic descriptions.
Key characteristics that distinguish BERTopic:
-
Semantic Understanding: Uses contextual embeddings that capture word meaning, synonyms, and contextual relationships better than traditional bag-of-words approaches.
-
Hierarchical Structure: Supports topic hierarchies and subtopics, allowing for multi-level topic exploration and analysis.
-
Modular Flexibility: Modular design allows customization of each component (embedding model, dimensionality reduction, clustering algorithm) to suit specific use cases.
-
Rich Visualization: Comprehensive visualization capabilities for topic exploration, including interactive plots, topic hierarchies, and temporal topic evolution.
See this page for more details about BERTopic:
https://maartengr.github.io/BERTopic/index.html
- Automatically organize large document collections.
-
Implementing Basic Topic Modeling with BERTopic
Let's start with a basic example using individual words to understand the fundamental concepts. This simplified example demonstrates the core functionality.
Install the required modules:
$ pip install bertopic
Python code:
$ vi topic-modeling.py
from sentence_transformers import SentenceTransformer from umap import UMAP from hdbscan import HDBSCAN from bertopic import BERTopic # sample data - in practice, you'd use full sentences or documents sentences = ['cats', 'dogs', 'elephants', 'birds', 'cars', 'trains', 'planes'] # initialize the sentence transformer model embedding_model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2") # generate embeddings embeddings = embedding_model.encode(sentences) # configure BERTopic with custom parameters + fit the model topic_model = BERTopic( embedding_model=embedding_model, umap_model=UMAP(n_components=5, random_state=42), hdbscan_model=HDBSCAN(min_cluster_size=2), verbose=True ).fit(sentences, embeddings) # display results print("Topics info:") print(topic_model.get_topic_info()) print("Topic 0 info:") print(topic_model.get_topic(0)) print("Topic 1 info:") print(topic_model.get_topic(1)) # create and save visualizations fig = topic_model.visualize_barchart() fig.write_html("bertopic-barchart-figure.html")Run the Python script:
$ python3 topic-modeling.py
Output:
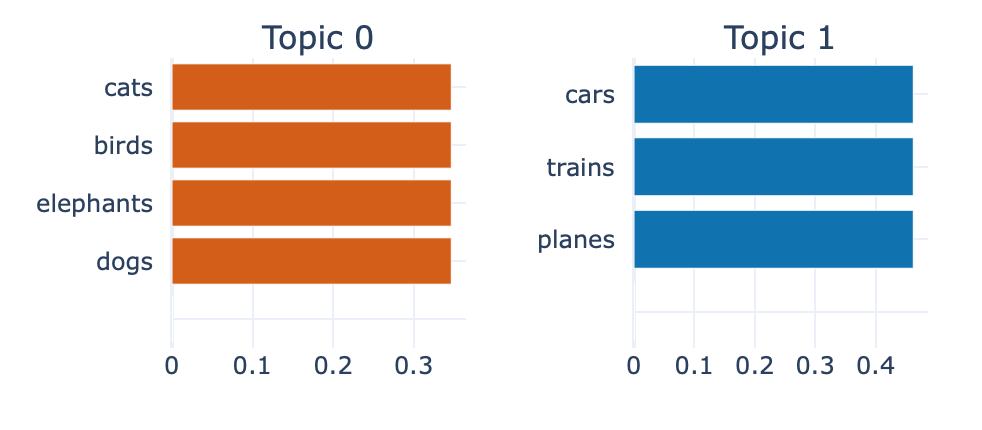
Topics info: Topic Count Name Representation Representative_Docs 0 0 4 0_cats_birds_elephants_dogs [cats, birds, elephants, dogs, , , , , , ] [birds, cats, dogs] 1 1 3 1_cars_trains_planes_ [cars, trains, planes, , , , , , , ] [planes, cars, trains] Topic 0 info: [ ('cats', np.float64(0.34657359027997264)), ('birds', np.float64(0.34657359027997264)), ('elephants', np.float64(0.34657359027997264)), ('dogs', np.float64(0.34657359027997264)), ('', 1e-05), ('', 1e-05), ('', 1e-05), ('', 1e-05), ('', 1e-05), ('', 1e-05) ] Topic 1 info: [ ('cars', np.float64(0.46209812037329684)), ('trains', np.float64(0.46209812037329684)), ('planes', np.float64(0.46209812037329684)), ('', 1e-05), ('', 1e-05), ('', 1e-05), ('', 1e-05), ('', 1e-05), ('', 1e-05), ('', 1e-05) ]Topics are represented by the main keywords extracted from the clustered documents, ranked by their importance scores (TF-IDF weights). Each topic name is automatically generated by concatenating the most representative keywords using underscores ("_"). The scores indicate how strongly each word represents the topic, with higher scores meaning stronger association. A special topic labeled "-1" may also appear, which typically includes outliers and documents that do not clearly fit into any specific topic cluster. This outlier category helps identify noise in the data or documents that require different clustering parameters.
Chart of the topics (Topic Word Scores): bertopic-barchart-figure.html
-
Advanced Topic Labeling with Language Models
One of BERTopic's most powerful features is the ability to generate human-readable topic labels using language models. Instead of relying solely on keyword concatenation, this approach leverages the natural language understanding capabilities of transformer models to create more intuitive and descriptive topic names.
The labeling process uses a carefully crafted prompt template that combines two key information sources:
-
Representative Documents: A subset of documents that best represent each topic will be inserted using the [DOCUMENTS] placeholder. These provide contextual examples of the topic's content.
-
Topic Keywords: The most important keywords that define the topic cluster will be inserted using the [KEYWORDS] placeholder. These provide additional context that helps the language model better understand the meaning of the text.
INPUT TEMPLATE: + Representative documents from the topic + Keywords that define the topic Documents: [DOCUMENTS] Keywords: [KEYWORDS] Task: Generate a concise, descriptive label for this topic.
OUTPUT: <human-readable topic labels>
Python code:
$ vi label-topic-modeling.py
from sentence_transformers import SentenceTransformer from umap import UMAP from hdbscan import HDBSCAN from bertopic import BERTopic from transformers import pipeline from bertopic.representation import TextGeneration sentences = ['cats', 'dogs', 'elephants', 'birds', 'cars', 'trains', 'planes'] # initialize the sentence transformer model embedding_model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2") # create embeddings embeddings = embedding_model.encode(sentences) # configure BERTopic with custom parameters + fit the model topic_model = BERTopic( embedding_model=embedding_model, umap_model=UMAP(n_components=5, random_state=42), hdbscan_model=HDBSCAN(min_cluster_size=2), verbose=True ).fit(sentences, embeddings) # prompt for topic labeling prompt = """These documents belong to the same topic: [DOCUMENTS] These keywords give details about the topic: '[KEYWORDS]'. Given these documents and keywords, what is this topic about?""" # initialize text generation pipeline # use a model ("google/flan-t5-small") to label the topics generator = pipeline("text2text-generation", model="google/flan-t5-small") # create representation model representation_model = TextGeneration( generator, prompt=prompt, doc_length=50, tokenizer="whitespace" ) # update topics with the generated labels topic_model.update_topics(sentences, representation_model=representation_model) # print the topic labels print(topic_model.get_topic_info())Run the Python script:
$ python3 label-topic-modeling.py
Output:
Topic Count Name Representation Representative_Docs 0 0 4 0_animals___ [animals, , , , , , , , , ] [birds, cats, dogs] 1 1 3 1_car___ [car, , , , , , , , , ] [planes, cars, trains]The actual output may show "car" instead of "transportation" due to the small dataset size and the language model's interpretation. With only 3 transportation-related words, the model may focus on the most frequent or representative term. In real-world applications with larger, more diverse datasets, language models typically generate more comprehensive and accurate topic labels.
-
Representative Documents: A subset of documents that best represent each topic will be inserted using the [DOCUMENTS] placeholder. These provide contextual examples of the topic's content.